Enterprise Object Oriented Information Taxonomy
The reality is that information management is no longer just about insulated concepts like Enterprise Content Management (ECM) or Knowledge Management (KM) systems. It’s multi-dimensional. It’s about business intelligence and analytics. It’s about using information for insights and engagement, but also to protect as an asset, to manage as a risk. These attributes provide the framework for all of IG, and enterprise taxonomy lays the groundwork for all of it.
The explosion of data often leads to fragmentation and data silos. For example, one line of business may refer to an account number while another refers to a social security number, and yet a third refers to a tax ID number. Different systems with different data characteristics. The result is confusion around search/retrieval, reporting, and lifecycle governance. Business intelligence opportunities are squandered, and discovery costs and effort are greatly complicated.
So how does “taxonomy” help the situation?
And what is an “object-oriented taxonomy” anyway?
AN OBJECT ORITENTED TAXONOMY
Wikipedia’s “Corporate taxonomy” page defines it as: “The hierarchical classification of entities of interest of an enterprise, organization or administration, used to classify documents, digital assets and other information.” I’m going to use another metaphor to describe the working concept. The first time many of us heard the word was back in high school, in a biological context: Kingdom, Phylum, Genus, Species, etc. Two of the key concepts behind this categorization are the inheritance and specialization of characteristics. Now, conceptually there is very little difference between the biological taxonomy and its object-oriented counterpart. Characteristics are inherited from the top parent levels, down to the children. Rather than inheriting limbs and backbones, we’re inheriting metadata, inheriting syntax, and context, and perhaps even retention requirements.
At each subsequent level that you define, you get a chance to specialize—to define some new characteristics that the parent didn’t have, but the child does. While this example may sound simplistic, in a complex data ecosystem, understanding these types of relationships can yield deep and meaningful insight into an organization‘s data. This type of insight may show relationships between traditionally siloed data that even its owners may not have seen. Best of all, the core principles behind this type of architecture design pattern can be used to model unstructured, semi-structured and fully structured data sets.
When we look at data in this way, we’re not creating anything new. We’re borrowing from a style of programming that’s pretty much ubiquitous these days, called object-oriented programming (OOP). At a high level, OOP is a way of managing clusters of code or content as objects. You create a blueprint for that “thing.” And then you create instances out of that blueprint. You can also expose or abstract parts of the object, depending on what your requirements are. Programmers today do this kind of stuff all the time; they model objects out of anything that you can give a noun too.
And objects come from classes. Classes contain properties – characteristics that describe the class (i.e., metadata). Think of a stencil or a cookie cutter. The shape of the stencil determines the shape of the letter. In our world, a document class defines the type of document we will deal with; a folder class determines the type of folder, etc.
This method of modeling data structures has been around for many years, but it gained traction in the 1990’s. Steve Jobs referred to it as a “brilliant, original idea” that he credited with helping him build software ten times faster, and better, at his venture NeXT (which would eventually become part of Apple in his return to that company). I submit to you the idea that similar outcomes can be realized by adopting an object-oriented approach to enterprise information governance.
INSURANCE CASE STUDY
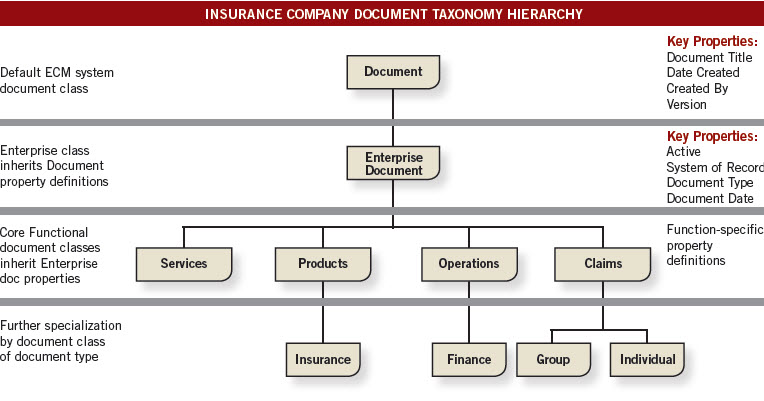
Let’s take a closer look at the guts of this architectural approach by imagining a high-level sample taxonomy for an insurance company:
At the top of the diagram, the out-of-box Document class contains several fundamental properties that are generic. They are the taxonomy designer’s starting framework.
The next level down is the first level of specialization: the Enterprise Document class. Its key properties are bound by the organization and make sense within the context of the organization. Every single document, every single record within the company will have at least these properties because they will be inherited downwards to every subclass of that base Enterprise Document class.
The third level is where you start to get creative. How do you determine that next “species” of the document? What do you use to tell the difference? It can get interesting because there are several potential choices here. Among the typical candidates are:
• Content-Centric Design: Document classes reflect their intrinsic content type. The classes are modeled around the meaning behind the underlying content. This marginalizes the relevance of organizational unit or function in the definition of the document, so if inheritance of security characteristics is important to the overall design, this is probably not the best choice
• Organizational Design: Document classes are modeled around the organization of the enterprise. In this design style, named LOB classes are used as parent containers of the document classes they use. The subsequent layers of the hierarchy then follow the organization down into smaller and smaller groupings. In this style, content is seen as a direct function of its parent LOB. This is a simple, security-driven model that makes it easy to map security between LOB users and their documents. However, a typical drawback with this design is that it’s too rigid, particularly for organizations that experience a lot of restructuring or mergers/acquisitions
• Functional Design: Document classes are modeled around the higher-level abstractions of the functions that an organization carries out. This may be different than an organizational design paradigm in that this approach captures many of the functional aspects of the corporation. These may mirror the organizational structure, but in a more abstract perspective by focusing on the function or processes for which the content is used.
This is the design style used in the insurance company example referenced above.
THE NUTS AND BOLTS: GETTING STARTED
So where do you begin?
Well, typically you begin with the front-line stakeholders, the end-users. The idea is to start with one LOB and get them involved right away. Holding an onsite requirements workshops is a good way to generate a checklist and synthesize an understanding of the following:
• Document characteristics (volume, format, input)
• Organizational structure
• Process
• Security
• Retention
• Reporting
You will probably find that the further down you get to answer as much as you can about these six interrelated dimensions, the closer you will be to understanding the full picture.
Your goal is to get the narrative of what drives the organization’s data. Remember, taxonomy development (whether intentional or not) has largely been a siloed activity, with department-specific
department-specific esoteric nuances. The enterprise-level brings it all together, and is at its best when the taxonomy is lean and flexible.
Also bear in mind that not all metadata is equal. After you’ve done your due diligence in figuring out property placement, your LOB stakeholders may come back and tell you that they need additional properties, once they realize what metadata actually is.
Once you have the metadata, it is time to make some decisions. Is this “required” metadata used for:
1. Search/Retrieval?
2. Lifecycle?
3. Reporting?
4. Process/Workflow?
Once you get the blueprint going, it should not be difficult to implement. If it is, you’ve probably done something wrong or the business has changed.
FUTURE OF TAXONOMIES
There is an interesting phenomenon being discussed in certain circles, with the advent of a new type of technologically enabled professional dubbed the citizen developer. These are people who can use various technology tools that were once only part of the IT department’s arsenal, to build business solutions. An enterprise object-oriented data design blueprint is the enabler of this type of paradigm. Whether it’s getting information into an API-ready state, or just enabling a common language—remember that stuff about the words we use—this technical data modeling is the path that allows positive momentum. Overall, organizations that adopt and manage a taxonomy should operate more efficiently, have a lower risk profile, and be set up to have a successful IG program.
EUGENE STAKHOV, CRM, CDIA+ IS A SENIOR ECM/IG SOLUTION ARCHITECT AT ENCHOICE, INC. GENE HAS PROVIDED CUSTOMERS WITH EXPERT GUIDANCE RANGING FROM ENTERPRISE TAXONOMY DEVELOPMENT TO TECHNICAL SYSTEM IMPLEMENTATION SOLUTIONS. HIS WORK INCLUDES IMPLEMENTING A HIGHLY VISIBLE REGULATORY COMPLIANCE INITIATIVE WHICH WON THE IBM INNOVATION IN TECHNOLOGY AWARD. GENE IS ALSO A LONG-TIME LEADER OF THE ARMA METROPOLITAN NYC CHAPTER, AND CURRENT PRESIDENT. HE MAY BE REACHED AT GSTAKHOV@ENCHOICE.COM[/glossary_exclude]
recent posts
You may already have a formal Data Governance program in [...]