Clean-Up with Content Analytics Technologies
[glossary_exclude]Shared drive remediation is a crucial activity for effective Information Governance (IG). Shared drive remediation helps to lower risks and costs by significantly reducing data volumes and providing accessibility and structure to unstructured information. Today’s discussion focuses on technologies available to help with the remediation and content migration process. These products fall under the technology category of content analytics (CA) also referred to as file analytics.
Classification is a key requirement for effective IG and CA—unstructured content, once tagged with proper metadata and classified, becomes structured and, therefore, findable, useable and manageable through its life cycle. Structuring shared drives using classification will move the organization a long way toward IG, but the use of content management systems/services, including properly deployed SharePoint sites, brings the greatest degree of operational effectiveness and life cycle control to achieve formal enterprise IG.
The goal of shared drive remediation is to migrate cleaned-up content to a system; if a system isn’t available or the content isn’t a good fit for it, then migrating content to a shared drive structured using a functional classification is the best option. There are many CA solutions; the kinds of content, the ultimate outcomes desired, volume of content and cost will help determine the options available to your organization. Systems are not meant for one-time clean-up projects; rather, continuous assessment of new content will help monitor the new folder structures to be sure content is being saved in the right place.
CA systems have varying capabilities:
- Metadata analysis – looks only at the file system (and/or SharePoint) metadata (properties). All systems conduct metadata analysis and often have pricing options for metadata-only analysis.
- Text analytics – further refines categorization of content, can search for personally identifiable information (PII) and other sensitive data, and identifies high-value content.
- Image analysis – groups like-images using graphical pattern matching; it does not require optical character recognition (OCR).
- Archive solutions – perform the above analytics but also ingest target content into their repository for ongoing classification, analysis, discovery, hold and disposition.
- SharePoint – Some solutions are tightly integrated with SharePoint information architecture for bi-directional updates of taxonomies and metadata.
- Additional functions – Some solutions offer e-discovery, email migration and classification term-extraction.
To some degree, the solution capabilities beyond pure CA are indicative of the product origin—products that started out as e-discovery solutions have strong capabilities in that area. Others originated as CA solutions and excel at grouping, remediating and migrating content. Still others originated as archiving solutions and have expanded to encompass CA and e-discovery capabilities. While manual analysis or Excel spreadsheets can be useful for a high-level content analysis, acting on content is a much greater challenge without a CA solution.
CA solutions follow roughly the same workflow:
- Discover content
System crawls content (starting at the root specified) and ingest metadata into a data store (not necessarily a relational database). If text analysis is done, the text will be added to a full text data store. Text analysis significantly slows down the crawl; therefore, a first cut at clean-up based on metadata will yield immediate results and reduce the content that will be ingested for full text analysis. This data store is your “data lake.”
- Cleanse Content
Analyze content, group content by like attributes, match to an existing classification scheme or use the CA system to build classification terms. Remediate redundant, outdated and trivial (ROT) content and purge or quarantine it. Using just metadata, this task can be completed across very high volumes of content and across multiple repositories for broad normalization. In addition, workflow is used for human identification of content groupings that cannot be automatically classified. Most CA solutions use artificial intelligence (AI) to constantly improve classification accuracy; others require a “document corpus” to train the analysis engine on syntax concepts to improve recognition. Extracted metadata can be rationalized and validated.
Another valuable analysis task identifies migration issues dependent on the target system; for example, file names or document types not supported by SharePoint, encrypted files, password protected files, undocumented file extensions, etc. These anomalies can be queued in workflow for review or quarantined prior to initiating migration activities.
- Identify sensitive data or business-critical data
Products that leverage text analytics use regular expressions (regex) to find social security numbers, credit card numbers and other PII or to locate tags that are critical for a business, such as contracts, intellectual property, etc. Some systems will leverage outside data sources to validate extracted data—e.g. a regular expression would be used to search for “contract number” pattern in the text. If a candidate is found, the value will be looked up against a database of valid contract numbers.
- Migration of content
Once you have clean, classified content, it can be migrated, using business rules and considering IG policies, to a new, properly classified shared drive, an enterprise content management (ECM) or content services solution, SharePoint site, or another repository. Content that is questionable can be queued in workflow for human analysis, and content with sensitive data can be migrated to quarantine, waiting for further analysis and action.
- Content rationalization
Now that content is clean, categorized and has validated metadata, it can be further analyzed to extract business data or be reorganized to meet business needs (mergers and acquisitions, divestiture, discovery, etc.).
- Ongoing governance
It is critical to monitor and maintain IG rules going forward to avoid facing the same mess a year or two down the road. CA systems offer various ways of automating classification tasks or monitoring repositories for compliance with the new taxonomies.
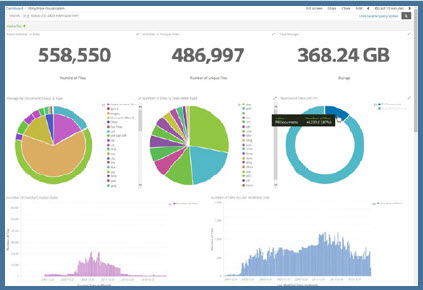
Content Analytics Dashboard
An example of the data visualization capabilities of these systems are shown in this dashboard graphic (above)—typical of all of the CA systems. It has no doubt become obvious that there are many considerations when cleaning up content and migrating it. CA tools, fortunately, formalize and automate the application of most business rules and IG policies. They manage content work processes to effect proper content groupings within a formal classification structure.
For more information on CA issues, efficient information organization, information governance, life cycle management and ongoing control, visit www.imergeconsult.com.
[/glossary_exclude]
recent posts
You may already have a formal Data Governance program in [...]